
Table of Contents
- Why PostgreSQL for SaaS?
- The Multi-Tenancy Challenge
- Three Multi-Tenancy Models
- Comparing the Models
- The Modern Approach: Shared Tables + Row-Level Security
- Setting Up Your Foundation
- What’s Next
- Further Reading
- Summary
Why PostgreSQL for SaaS?
When building a Software-as-a-Service application, your database choice is one of the most consequential decisions you’ll make. PostgreSQL has emerged as the go-to choice for SaaS applications, and for good reason:
- Row-Level Security (RLS): Native support for tenant isolation at the database level
- JSONB: Flexible schema for tenant-specific customizations without migrations
- Mature ecosystem: Battle-tested tools like PgBouncer, pg_dump, and logical replication
- Cost-effective: No per-seat licensing, scales from hobby projects to enterprise
- Extensions: PostGIS, pg_cron, pgvector, and hundreds more for specialized needs
But choosing PostgreSQL is just the beginning. The real challenge lies in how you structure your data to serve multiple tenants efficiently, securely, and at scale.
The Multi-Tenancy Challenge
In a SaaS application, you’re serving multiple customers (tenants) from a single codebase and infrastructure. Each tenant expects:
- Data isolation: Their data must never leak to other tenants
- Performance: One tenant’s heavy usage shouldn’t affect others
- Customization: Ability to configure features for their needs
- Compliance: Meeting regulatory requirements (GDPR, SOC2, HIPAA)
The architecture pattern you choose will determine how easily you can deliver on these expectations.
Three Multi-Tenancy Models
There are three primary approaches to multi-tenancy in PostgreSQL, each with distinct trade-offs:
1. Database-per-Tenant
Each tenant gets their own PostgreSQL database.
Pros:
- Strongest isolation: impossible for data to leak between tenants
- Easy per-tenant backup and restore
- Simple to relocate a tenant to different infrastructure
- Per-tenant performance tuning possible
Cons:
- Connection overhead: each database requires separate connection pools
- Schema migrations must run N times (once per tenant)
- Harder to run cross-tenant analytics
- Doesn’t scale well beyond ~100-500 tenants
Best for: Enterprise SaaS with strict compliance requirements, small number of high-value tenants.
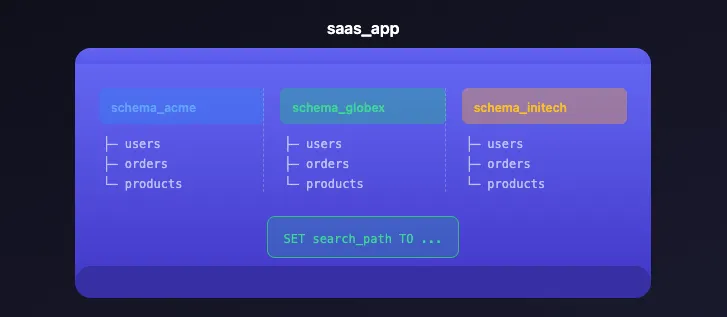
2. Schema-per-Tenant
Tenants share a database but each gets their own PostgreSQL schema.
Pros:
- Good isolation through schema boundaries
- Single connection pool serves all tenants
- Per-tenant backup still possible (pg_dump with —schema)
- Easier migrations than database-per-tenant
Cons:
- Schema proliferation can slow down PostgreSQL (catalog bloat)
- Still requires per-tenant migration execution
- Cross-tenant queries require dynamic SQL
- Practical limit around 1,000-10,000 tenants
Best for: Mid-market SaaS with moderate tenant count, need for logical separation.
3. Shared Tables with Tenant ID
All tenants share the same tables, distinguished by a tenant_id column.

Pros:
- Most efficient resource utilization
- Single migration runs for all tenants
- Cross-tenant analytics are straightforward
- Scales to millions of tenants
- Simpler connection pooling
Cons:
- Data isolation depends entirely on application logic (or RLS)
- A bug can expose data across tenants
- Noisy neighbor problems without careful design
- Harder to extract a single tenant’s data
Best for: B2C SaaS, high-volume applications, startups needing to move fast.
Comparing the Models
| Factor | Database-per-Tenant | Schema-per-Tenant | Shared Tables |
|---|---|---|---|
| Isolation | Strongest | Strong | Application-enforced |
| Tenant Scale | ~100-500 | ~1,000-10,000 | Millions |
| Migration Complexity | High (N runs) | Medium (N runs) | Low (1 run) |
| Resource Efficiency | Low | Medium | High |
| Cross-tenant Queries | Very Hard | Hard | Easy |
| Compliance Fit | Excellent | Good | Requires RLS |
| Connection Overhead | High | Low | Lowest |
The Modern Approach: Shared Tables + Row-Level Security
For most SaaS applications in 2026, the shared tables with Row-Level Security approach offers the best balance of simplicity, scalability, and safety.
Here’s a preview of what this looks like:
-- Every table includes tenant_idCREATE TABLE orders ( id UUID PRIMARY KEY DEFAULT gen_random_uuid(), tenant_id UUID NOT NULL REFERENCES tenants(id), user_id UUID NOT NULL, total NUMERIC(10,2) NOT NULL, created_at TIMESTAMPTZ DEFAULT now());
-- Index for tenant-scoped queriesCREATE INDEX idx_orders_tenant ON orders(tenant_id);
-- Enable RLSALTER TABLE orders ENABLE ROW LEVEL SECURITY;
-- Policy ensures tenants only see their own dataCREATE POLICY tenant_isolation ON orders USING (tenant_id = current_setting('app.current_tenant')::UUID);With this pattern:
- The database itself enforces tenant isolation
- Even a bug in your application code won’t leak data
- A single query plan works for all tenants
- You can scale to massive tenant counts
We’ll dive deep into RLS implementation in Part 3 of this series.
Setting Up Your Foundation
Before we proceed to specific patterns, let’s establish a minimal SaaS schema:
-- Core tenant tableCREATE TABLE tenants ( id UUID PRIMARY KEY DEFAULT gen_random_uuid(), name TEXT NOT NULL, slug TEXT UNIQUE NOT NULL, plan TEXT NOT NULL DEFAULT 'free', created_at TIMESTAMPTZ DEFAULT now(), settings JSONB DEFAULT '{}');
-- Users belong to tenantsCREATE TABLE users ( id UUID PRIMARY KEY DEFAULT gen_random_uuid(), tenant_id UUID NOT NULL REFERENCES tenants(id), email TEXT NOT NULL, name TEXT, role TEXT NOT NULL DEFAULT 'member', created_at TIMESTAMPTZ DEFAULT now(), UNIQUE(tenant_id, email));
-- Example business entityCREATE TABLE projects ( id UUID PRIMARY KEY DEFAULT gen_random_uuid(), tenant_id UUID NOT NULL REFERENCES tenants(id), name TEXT NOT NULL, description TEXT, created_at TIMESTAMPTZ DEFAULT now());
-- Indexes for common query patternsCREATE INDEX idx_users_tenant ON users(tenant_id);CREATE INDEX idx_users_email ON users(tenant_id, email);CREATE INDEX idx_projects_tenant ON projects(tenant_id);Key design decisions here:
- UUIDs over auto-increment: Prevents enumeration attacks and simplifies data migration
- tenant_id on every table: Consistent pattern makes RLS policies straightforward
- JSONB for settings: Allows tenant-specific configuration without schema changes
- Composite unique constraints:
(tenant_id, email)allows same email across tenants
What’s Next
In this series, we’ll build out a production-ready SaaS database layer piece by piece:
- This post: Multi-tenancy models and foundational schema
- Multi-Tenancy Patterns Compared: Deep dive into when to use each model
- Row-Level Security: Implementing bulletproof tenant isolation
- Connection Pooling: Scaling connections with PgBouncer
- Schema Design Patterns: Audit logs, soft deletes, and more
- Indexing Strategies: Optimizing multi-tenant queries
- Table Partitioning: Handling growth with partitions
- Background Jobs: Async processing with PostgreSQL
Each post will include practical code you can adapt for your own SaaS.
Further Reading
- PostgreSQL Row Level Security Documentation
- Citus Data Multi-Tenant Tutorial
- AWS Multi-Tenant SaaS Architecture
Summary
Choosing your multi-tenancy model is a foundational decision that affects everything from security to scaling. For most SaaS applications, shared tables with Row-Level Security provides the best combination of simplicity, performance, and safety.
In the next post, we’ll compare these patterns in more detail with real-world benchmarks and decision frameworks to help you choose the right approach for your specific use case.